In this article
Top 30 System Design Interview Questions (+ Quiz!)
 Ekene Eze
Ekene Eze
Interviews can be tricky and sometimes even intimidating. They often come with a sense of uncertainty, since in most cases, you have little or no control over the questions being asked. System design interviews raise the bar even further because they focus on a core skill required to build complex software systems, whether for startups or major big tech companies like Google, Amazon, and Facebook.
Even experienced developers with years in the field often find system design interviews challenging. The difficulty isn’t only about technical knowledge; it’s also about clearly explaining your thought process, handling ambiguous requirements, and making thoughtful decisions under pressure. Companies rely on these questions to evaluate whether you can design solutions for real-world, large-scale problems.
In this guide, I’ll walk you through 30 essential system design interview questions. We’ll start with the basics, move into more advanced topics, and also explore scenario-based questions with practical strategies for answering them. By the end, you’ll feel more confident approaching system design concepts and know how to apply these patterns effectively.
To make preparation easier, I’ve included a set of flashcards for quick self-testing. And if you’d like to go deeper into the concepts covered here, be sure to check out the system design roadmap.
Getting ready for system design interview
You’ve probably heard the saying, “Interviewing is a skill.” It means it takes conscious effort and practice to get better. Just like any other skill, you need to strengthen the basics of both soft and technical skills so your answers highlight your strengths and show you’re the right fit for the role. Here are a few key areas to brush up on before heading into your system design interview.
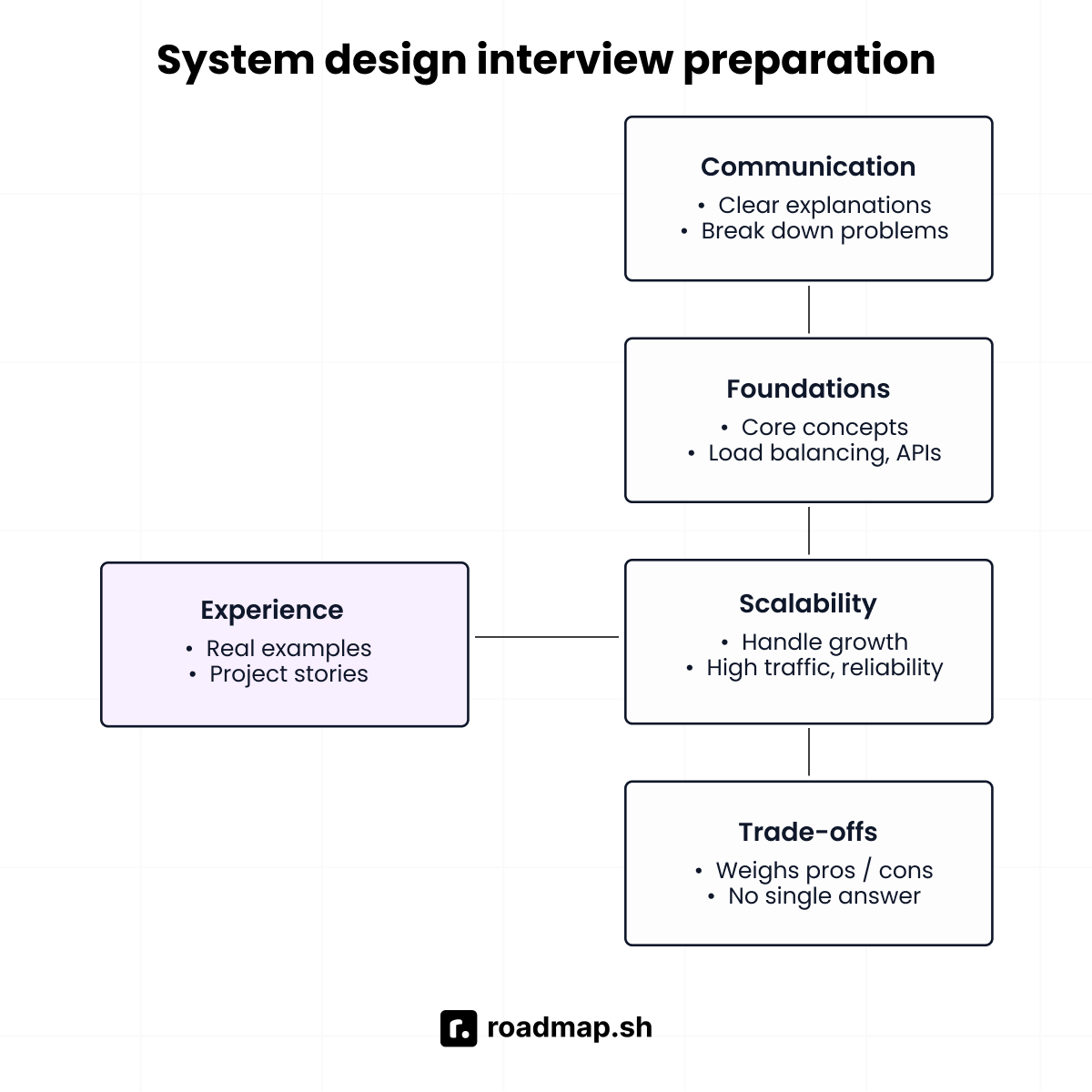
Communication skills: Practice explaining your thought process clearly and concisely. Interviewers want to see how you break down problems and reason through trade-offs.
Foundational concepts: Review core topics such as load balancing, caching, databases (SQL vs. NoSQL), and APIs. These come up in almost every system design conversation.
Scalability and reliability: Be ready to discuss strategies for handling growth, high traffic, fault tolerance, and disaster recovery.
Trade-offs and decision making: System design isn’t about one “right” answer. Show that you can weigh pros and cons and make practical choices.
Previous experience: Think of examples from projects you’ve worked on that demonstrate how you’ve applied these concepts in real-world scenarios.
In some cases, interviewers might begin with general questions like:
“How long have you been working as a software engineer or backend developer?” (depending on your role)
“How would you rate your proficiency in database systems and schema design?”
“What are some common design patterns you’ve used?”
These warm-up questions usually help set the tone and make you feel more comfortable. Even if some of this information is already on your CV or resume, be ready to talk about it. Practice giving crisp, honest answers that reflect your system design experience.
With that foundation in place, let’s move on to the specific system design questions you should get familiar with as you prepare for your interview.
Test yourself with Flashcards
You can either use these flashcards or jump to the questions list section below to see them in a list format.
What is consistent hashing, and why is it useful?
Consistent hashing is a technique for distributing requests or data across many servers. The key advantage is that when servers are added or removed, only a small portion of the data needs to move instead of everything being reshuffled.
Think of the servers arranged in a circle. Each piece of data is assigned a position on that circle and is stored on the first server you encounter when moving clockwise. This setup makes it easy to know where data belongs, even when the number of servers changes.
A well-known example is Amazon DynamoDB. During high-traffic events like Black Friday, DynamoDB can add extra servers to handle demand. Because it uses consistent hashing, only a fraction of the data needs to be relocated to the new servers. This keeps the overall system architecture stable and responsive.
Consistent hashing is useful because:
It makes scaling smoother since only part of the data moves.
It improves fault tolerance because other servers can take over when one fails.
It balances requests more evenly with the help of virtual nodes.
Questions List
If you prefer to see the questions in a list format, you can find them below.
Beginner's system design interview questions
What is consistent hashing, and why is it useful?
Consistent hashing is a technique for distributing requests or data across many servers. The key advantage is that when servers are added or removed, only a small portion of the data needs to move instead of everything being reshuffled.
Think of the servers arranged in a circle. Each piece of data is assigned a position on that circle and is stored on the first server you encounter when moving clockwise. This setup makes it easy to know where data belongs, even when the number of servers changes.
A well-known example is Amazon DynamoDB. During high-traffic events like Black Friday, DynamoDB can add extra servers to handle demand. Because it uses consistent hashing, only a fraction of the data needs to be relocated to the new servers. This keeps the overall system architecture stable and responsive.
Consistent hashing is useful because:
It makes scaling smoother since only part of the data moves.
It improves fault tolerance because other servers can take over when one fails.
It balances requests more evenly with the help of virtual nodes.
Explain the difference between vertical scaling and horizontal scaling.
Scaling means increasing your system’s capacity so it can handle more users or requests. There are two main ways to do this:
Vertical scaling means making a single machine stronger by adding more CPU, RAM, or storage. It’s similar to upgrading your laptop with more memory so it runs faster.
Horizontal scaling means adding more machines to share the workload. Imagine connecting several laptops so each one handles part of the load.

In real systems:
Vertical scaling is easier to set up, but it has limits. A single machine can only get so powerful, and if it fails, everything goes down.
Horizontal scaling is harder to manage, but it can grow almost without limit. If one machine fails, others can take over, making the system more reliable.
What are load balancers, and why are they used?
A load balancer helps manage traffic across multiple servers. Instead of sending all requests to a single server, it distributes them so no server gets overwhelmed.
It works like a traffic director at a busy intersection, guiding cars to different roads so none of them get jammed. In the same way, a load balancer routes requests to the server that can handle them best. It can use simple methods like round robin (sending requests one by one to each server) or smarter methods like sending new requests to the server with the fewest active connections.
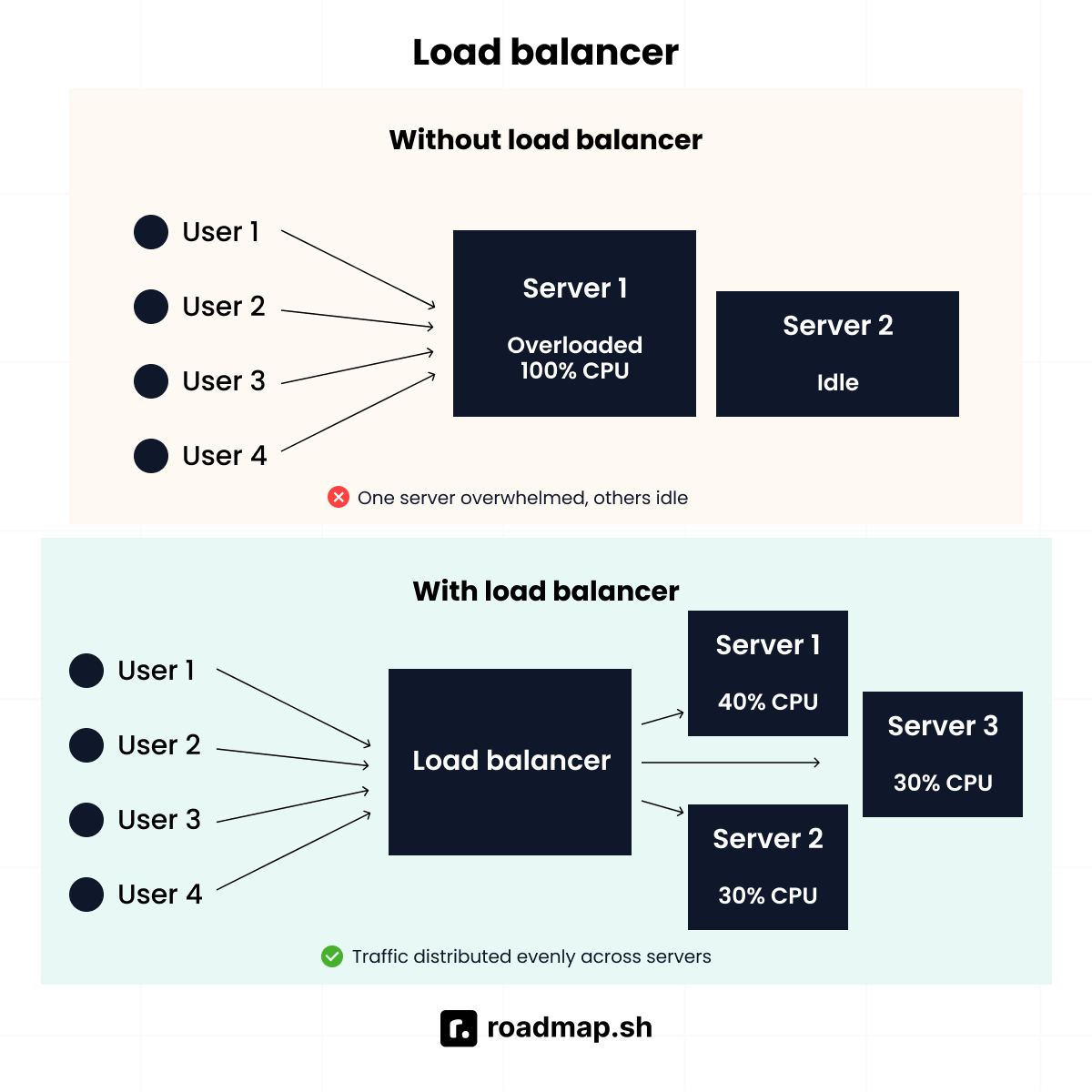
Large-scale applications like Amazon and Instagram rely on load balancers to stay fast and reliable. Without them, a single server could crash under heavy traffic, taking the whole application down.
Load balancers are useful because they:
Prevent servers from being overloaded
Improve reliability by redirecting traffic if a server fails
Keep performance smooth, even under heavy demand
4. Explain the CAP theorem with examples.
The CAP theorem describes the trade-offs in a distributed system. It states that when your system is spread across multiple servers, you can only guarantee two out of three properties at the same time.
Consistency (C): Every user sees the same data at the same time.
Availability (A): Every request gets a response, even if some servers are down.
Partition tolerance (P): The system continues to work even if parts of the network can’t communicate.
Since network partitions are always possible, most systems must choose between Consistency and Availability.
Examples:
A banking app (CP) may prioritize Consistency and Partition Tolerance. It’s better to be temporarily unavailable than to show the wrong account balance.
A social media platform (AP) like Facebook often chooses Availability and Partition Tolerance. If there’s a network issue, you might see an older feed rather than getting an error.
What is caching? Where would you place a cache in a system?
Caching means storing frequently used data in fast memory so it can be retrieved quickly. This reduces response time and lowers the load on the main database.
A simple analogy is keeping your coffee mug on your desk instead of walking to the kitchen every time you need it. It saves time and effort.
Depending on the use case, caching can be placed on:
Client-side: In the browser, to store static assets like images, stylesheets, or scripts.
Application-level: In the server’s memory using tools like Redis or Memcached. This is useful for things like user sessions or repeated queries.
Database-level: To store the results of expensive queries so they don’t need to run repeatedly.
For example, a social media platform like Reddit caches popular posts so that when a thread goes viral, millions of users can see it without overwhelming the database.
Explain CDN (Content Delivery Network) and when to use it.
A CDN is a network of servers placed around the world that store and deliver static content like images, videos, and stylesheets. By bringing content geographically closer to users, CDNs reduce latency and speed up delivery.
It’s like having local warehouses in different cities so customers don’t have to wait for packages to ship from far away.
You’ll use CDN when you have:
Media-heavy sites (videos, images, large files)
Global users who need a fast loading time
What is sharding, and how does it help with scalability?
Sharding means splitting a database into smaller, independent parts called shards, with each shard containing a subset of the data, usually based on a key such as user ID. This makes scaling easier because no single database has to handle all the load. Instead, each shard is responsible for only part of the data.
In practice, a ride-sharing app like Uber could shard data by city, so each region handles only local trips. This keeps queries fast as the user base grows worldwide.
When would you choose SQL vs. NoSQL?
The choice between SQL and NoSQL depends on your data and system requirements.
SQL (e.g., PostgreSQL, MySQL): Best for structured data, complex queries, and transactions that must always be correct. A good example is banking ledgers, where accuracy and consistency are critical.
NoSQL (e.g., MongoDB, Cassandra): Best for unstructured or semi-structured data, massive scale, and fast writes. Social apps often use NoSQL to store flexible user profiles or logs that don’t fit neatly into tables.
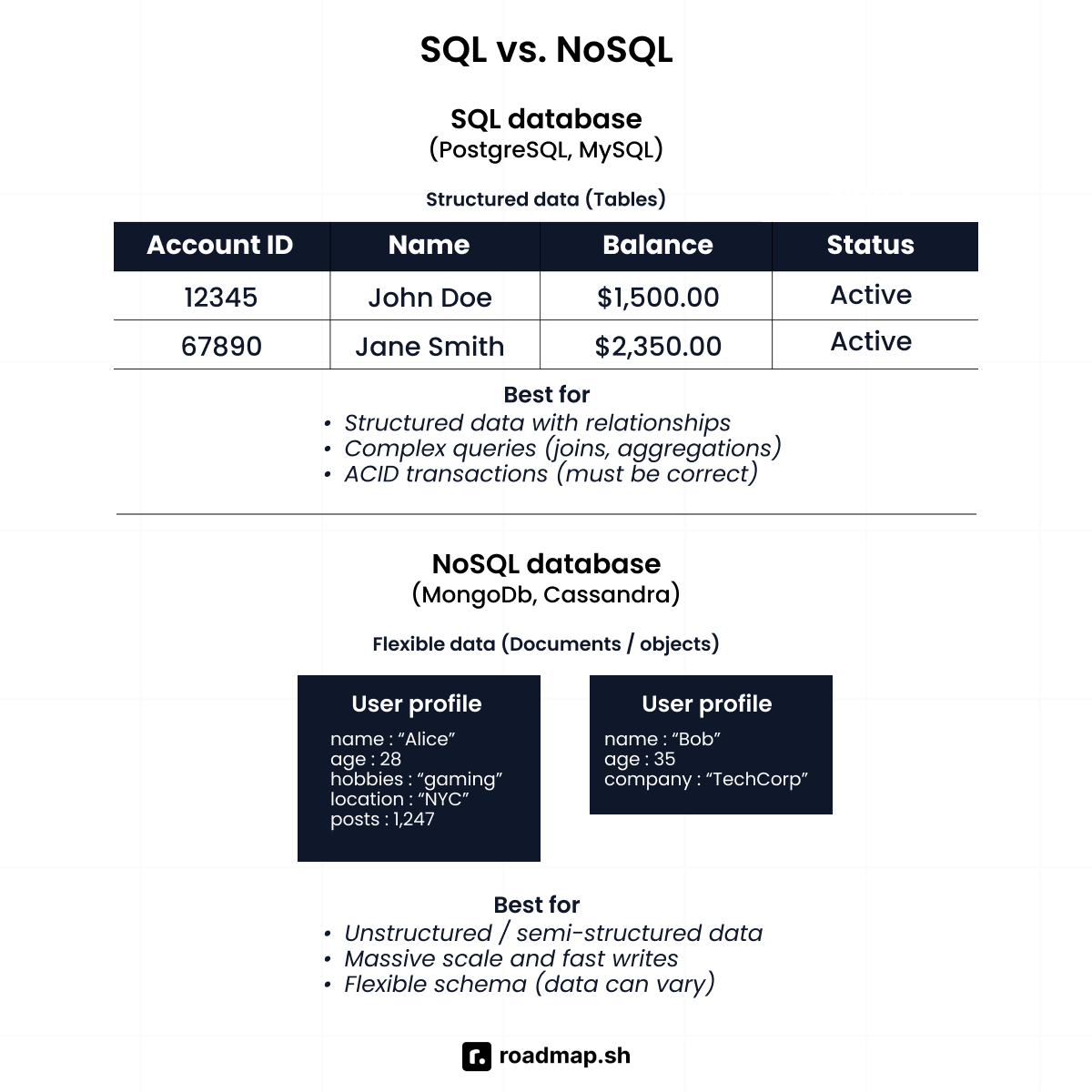
As a rule of thumb, use SQL when you need strong consistency and relational data, and use NoSQL when you need flexibility and scalability.
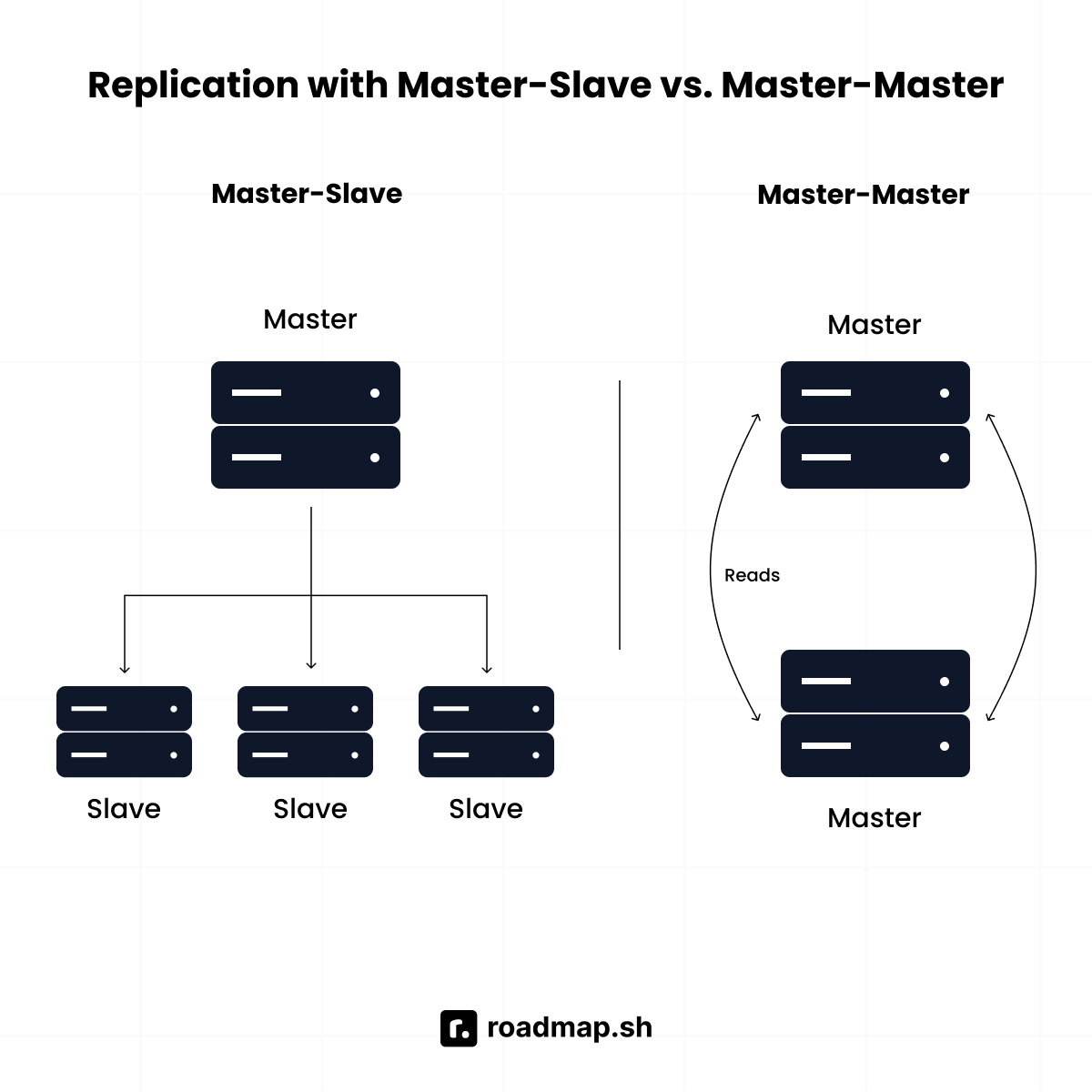
Explain the concept of replication and its types (Master-Slave, Master-Master).
Replication means copying data across multiple servers so the system is more reliable and can handle more reads. It helps improve fault tolerance and scalability, but may introduce trade-offs in complexity.
Types of replication:
Master-Slave: One server (master) handles all writes, while one or more slaves maintain copies for reads. This setup is simple and great for backups. For example, MySQL often uses this model.
Master-Master: Multiple servers can handle writes, and they sync with each other. This is more complex because conflicts can happen, but it’s powerful for global apps that need low-latency writes, such as Google Spanner.
What is eventual consistency vs. strong consistency?
Consistency describes how up-to-date the data is across different servers.
Strong consistency: Every read returns the latest write. This guarantees accuracy but may reduce availability. For example, a stock trading platform must use strong consistency so users don’t oversell shares.
Eventual consistency: Reads may return slightly outdated data, but all copies catch up eventually. This improves availability and performance. For example, Amazon DynamoDB uses eventual consistency for shopping carts, where a small delay is acceptable.
The key idea is that strong consistency guarantees correctness right away, while eventual consistency favors uptime and speed.
With the basics covered, interviewers now want to see how you combine fundamentals to build real-world systems. These questions test your understanding of the “glue” that keeps applications running under pressure and the choices you make to balance performance, reliability, and scalability.
Intermediate system design interview questions
How would you design a rate limiter?
A rate limiter controls how many requests a client can make within a given time, protecting systems from abuse like spam or denial-of-service attacks.
Common approaches include:
Token bucket: Tokens are added at a fixed rate. Each request uses one token; if none remain, the request is blocked.
Sliding window: Tracks recent requests within a time window and blocks if too many occur too quickly.
In practice, APIs often implement rate limiting in middleware with Redis for distributed counting. When limits are exceeded, requests typically return a 429 Too Many Requests error.
How do message queues (e.g., Kafka, RabbitMQ) help in system design?
Message queues let services communicate asynchronously. Instead of calling each other directly, one service sends a message to a queue, and another service processes it later. Popular queuing services are:
Kafka: Optimized for high-throughput event streams (e.g., logs, analytics)
RabbitMQ: Great for reliable task queues and guaranteed delivery
For example, an e-commerce order confirmation can be queued so the checkout process doesn’t block if the payment service is slow. This makes systems more resilient under heavy load, such as during Black Friday sales.
Explain how a distributed lock works.
A distributed lock ensures that in a system with many servers, only one process at a time can perform a critical action. For example, in a banking app, a distributed lock can prevent two servers from withdrawing money from the same account at the same time.
Tools like Redis (using SETNX with expirations) and ZooKeeper are commonly used to implement distributed locks and avoid race conditions.
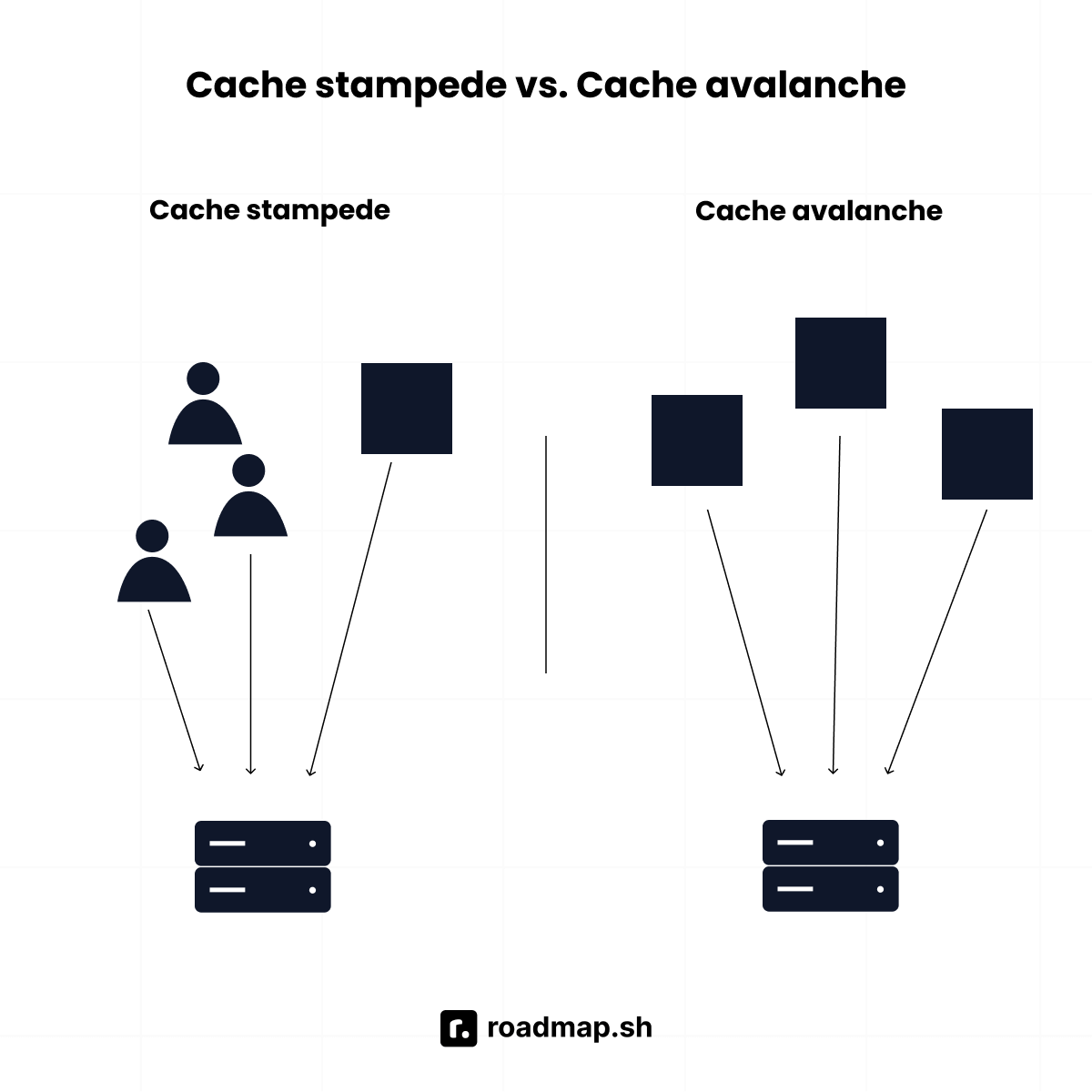
How do you prevent a cache stampede or cache avalanche?
A cache stampede happens when many requests hit an expired cache at the same time, overloading the database. To prevent this, you can:
Use early expiration (refresh before expiry).
Apply request coalescing with mutex locks so only one request updates the cache.
Pre-warm popular keys before they expire.
A cache avalanche happens when many cache entries expire at once, causing a sudden load spike. To fix this, you can:
Use staggered TTLs with random expiration buffers.
Apply write-through caching so the cache updates alongside the database.
What’s the difference between synchronous vs. asynchronous communication in distributed systems?
In synchronous, the sender waits for a response. It’s simple but can cause cascading failures if one service is slow. A common example is an HTTP request between microservices. While in
asynchronous, the sender adds a message to a queue or event stream and continues. It’s more resilient and scalable but harder to track end-to-end.
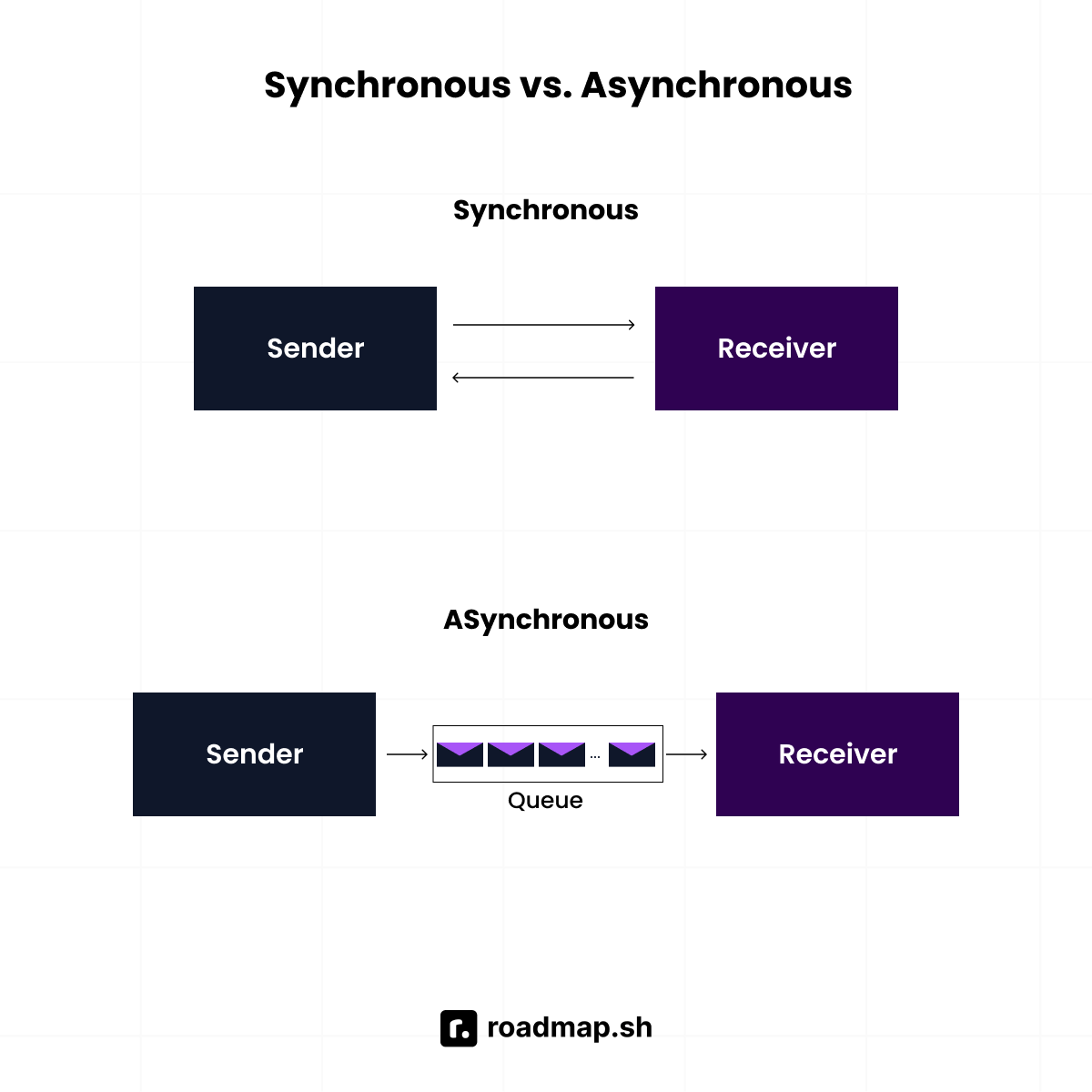
A practical example of asynchronous is how Spotify updates a playlist while the app is still responsive, even if downstream services are busy.
How do you handle database schema migrations in large systems?
Schema changes can’t be done all at once in large systems without downtime. Best practices include:
Using tools like Flyway or Liquibase to track changes with version control
Rolling out changes in a backward-compatible way (e.g., add new columns before removing old ones)
Using blue-green deployments or phased rollouts for zero downtime
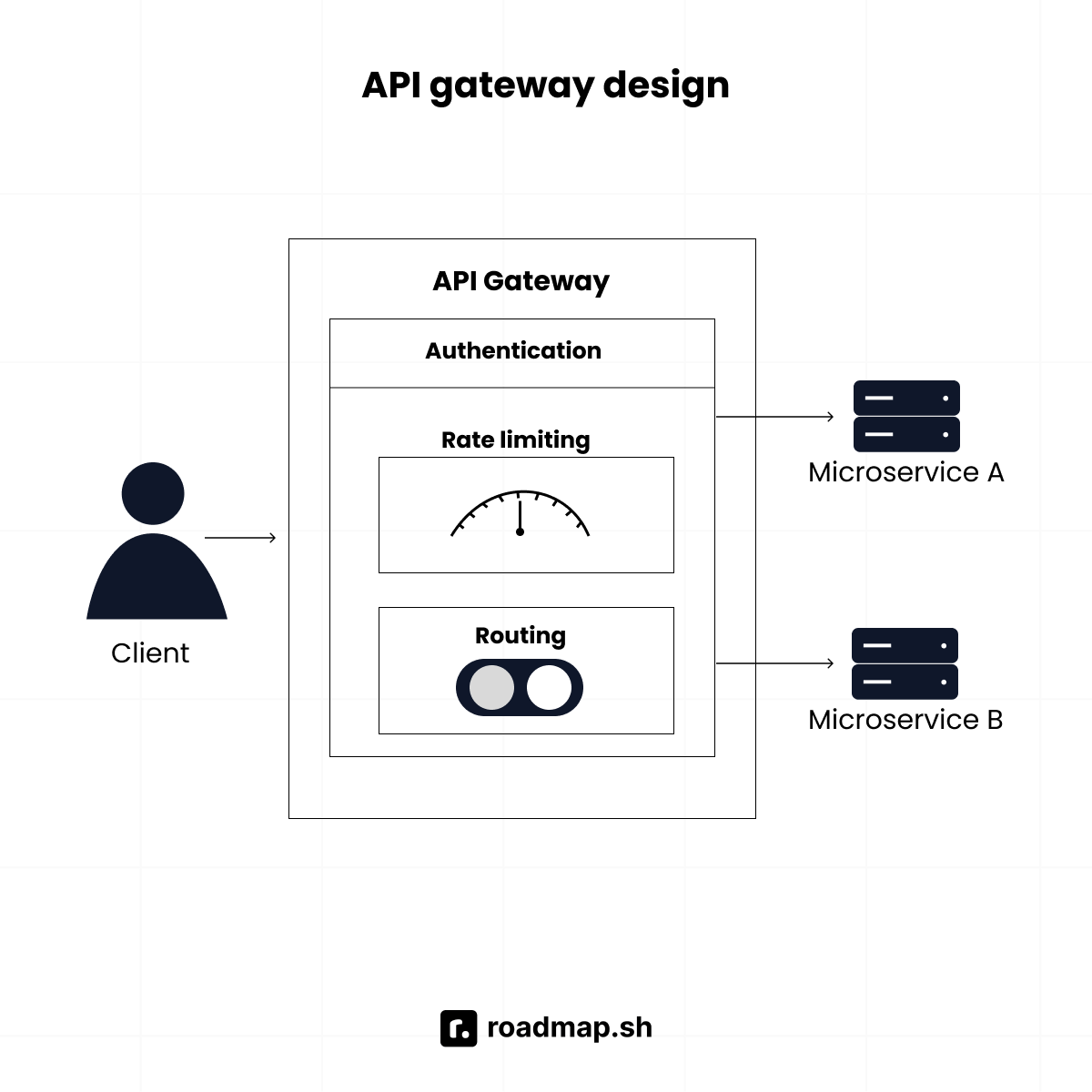
How would you design an API gateway?
An API gateway is a single entry point for clients, sitting in front of microservices. It typically handles:
Authentication and authorization
Rate limiting
Request routing and aggregation
Request and response transformation
Load balancing
Key considerations when designing an API gateway include:
Performance: handle high throughput with low latency.
Availability: avoid single points of failure.
Security: protect sensitive data in transit.
Observability: collect metrics for monitoring.
After the design, deployment can be on a managed service (such as AWS API Gateway or Azure API Management) or self-hosted (using tools like NGINX, Traefik, or Envoy).
Explain the role of reverse proxies.
A reverse proxy sits between clients and backend servers. It can:
Terminate SSL/TLS connections
Perform caching and compression
Load balance requests across servers
Hide backend details for security
Examples of reverse proxies are Nginx and HAProxy.
How would you design a logging and monitoring system for microservices?
A distributed logging and monitoring system must gather data from many services and turn it into actionable insights.
Logging architecture:
Collection: Each service writes structured logs (e.g., JSON).
Shipping: Log shippers like Fluentd or Filebeat send logs to an aggregator.
Storage: Centralized global file storage like Elasticsearch or AWS CloudWatch.
Analysis: Query and visualization tools like Kibana or Grafana.
Monitoring layers:
Infrastructure: CPU, memory, disk, network usage.
Application: Request rates, response times, error rates.
Business: Metrics such as user signups, transaction volumes, and revenue.
Explain how you’d design a notification system (e.g., push, SMS, email).
A notification system delivers updates through multiple channels such as push, SMS, or email.
Key components include:
Notification service: Central coordinator
Message queue: Buffer for high-volume notifications
Channel handlers: Specialized processors for each channel
Template engine: Generate personalized content
Delivery tracking: Monitor success/failure rates
When building this system, think about it in stages:
Ingestion: Use a queue (Kafka, RabbitMQ) to accept and buffer incoming events reliably.
Processing: Workers consume events from the queue, enrich them if needed, and dispatch them through the right provider (e.g., Twilio for SMS).
Delivery Guarantees: Implement retries, apply rate limits, and respect user preferences to ensure reliable and personalized delivery.
Combining basic concepts and applying them to real-world problems is important, but interviewers also want to see how you handle complexity at scale. They’re testing your understanding of how systems behave under pressure, how you maintain performance, and how well you can work with systems that people depend on every day.
Advanced system design interview questions
How would you design a collaborative document editing system (like Google Drive or Dropbox)?
A collaborative editor must let multiple users edit the same document in real time without conflicts. Key components include:
Conflict resolution: Use Operational Transformation (OT) or Conflict-free Replicated Data Types (CRDTs) so simultaneous edits don’t overwrite each other.
Real-time updates: Use WebSockets for low-latency sync between clients and servers.
Backend coordination: A pub/sub system like Redis broadcasts updates to all connected users.
Storage: Use a relational database like PostgreSQL, sharded by document ID for scalability.
How would you design a URL shortening service (like bit.ly)?
A URL shortener maps long links to short, shareable keys while handling billions of lookups. Designing it involves:
Key generation: Use Base62 encoding of an auto-increment ID or generate hashes for uniqueness.
Storage: Use a distributed NoSQL database like Cassandra for fast writes and reads.
Performance: Cache popular URLs in Redis to reduce DB lookups.
Extras: Collect analytics (clicks, referrers, geolocation).
How would you design a social media feed system (e.g., Facebook newsfeed, Twitter timeline)?
Feeds must combine real-time updates with ranking at scale. Designing it involves:
Fan-out on write: Push new posts directly into followers’ feeds. Fast for active users, but expensive for celebrities with millions of followers.
Fan-out on read: Store posts centrally and build the feed when a user opens it. Saves storage but increases query load.
Ranking: Use ML models to rank posts by relevance, not just recency.
Storage and caching: Use sharded databases and in-memory caches for hot feeds.
How would you design a search autocomplete system?
Autocomplete suggests results as the user types, so it must be fast and continuously updated. Core components to consider when designing it include:
Data structure: Use a Trie or inverted index to store prefixes efficiently.
Search engine: Systems like Elasticsearch can index and return prefix matches quickly.
Caching: Store common prefixes in Redis for low-latency lookups.
Error handling: Apply fuzzy matching (e.g., Levenshtein distance) to handle typos.
How do you design a payment processing system (like Stripe/PayPal)?
Payments require security, reliability, and regulatory compliance. Building a payment system will cover:
Microservices: Separate services for authentication, transaction handling, fraud detection, and notifications.
Asynchronous workflows: Use queues for retries and idempotency to prevent duplicate charges.
Compliance: Follow PCI standards and encrypt sensitive data.
Integration: Connect with banks and card networks via APIs.
Idempotency: Ensure retries don’t double-charge users.
How would you design an e-commerce checkout system?
Checkout is mission-critical and must be both consistent and resilient. Designing it entails:
Atomic operations: Use saga patterns or two-phase commit (2PC) to ensure cart, payment, and inventory remain in sync.
Queues: Offload order fulfillment (shipping, emails) to async workers.
Inventory locking: Temporarily hold stock during checkout to avoid overselling.
How do you design a real-time chat system (like WhatsApp/Slack)?
Global chat services handle billions of messages daily while ensuring instant delivery, conversation history, and multimedia support. The architecture includes:
Transport: WebSockets for persistent, bidirectional communication.
Storage: Write messages to distributed storage (e.g., Cassandra for time-series data).
Group chats: Use pub/sub systems to broadcast messages to multiple users.
Scale: Use partitioning and sharding for chat rooms with millions of users.
Security: End-to-end encryption for privacy.
How do you design a recommendation system (e.g., Netflix, Amazon)?
Recommendation systems analyze user behavior and content attributes to suggest relevant items, directly impacting engagement and revenue. Designing a system that caters to this need requires:
Algorithms: Collaborative filtering (similar users/items) or content-based models (item attributes).
Batch layer: Offline training with Spark or Hadoop on historical data.
Real-time layer: Update recommendations with Kafka streams based on new activity.
Serving layer: Expose recommendations through a fast API with caching.
How do you design a video streaming service (like YouTube/Netflix)?
Video streaming platforms handle massive amounts of video content, global distribution, and millions of concurrent viewers while maintaining high quality and minimal buffering. It needs to balance storage, delivery, and adaptive playback. Designing it involves:
Encoding: Transcode videos into multiple formats and bitrates.
Storage: Store in object stores (e.g., S3) with metadata in sharded databases.
Delivery: Use CDNs for global distribution.
Adaptive playback: Use HLS or MPEG-DASH to adjust video quality based on bandwidth.
How would you design a ridesharing app backend (Uber/Lyft)?
Ridesharing platforms coordinate millions of drivers and riders in real-time while optimizing routes, pricing, and resource allocation. Architecting a ridesharing platform includes:
Geospatial indexing: Use data structures like Quadtrees or GeoHash for nearby driver searches.
Matching service: Match riders with drivers in real time, factoring in distance, ETA, and surge pricing.
Messaging: Use WebSockets or push notifications for trip updates.
Scalability: Shard by city or region for local performance.
In addition to the technical interviews, you may also face scenario-based questions that introduce ambiguity and incomplete information. Interviewers use these to see how you deal with uncertainty, whether you ask clarifying questions, make reasonable assumptions, and adjust your design as new constraints surface. They want to understand not just your technical depth, but how you draw on past experiences to guide decisions, weigh trade-offs, and avoid pitfalls.
These questions often mix technical, product, and communication aspects. They typically follow one or more patterns:
Ambiguous requirements: Like “Design a system to handle messaging between users. The company hasn’t decided whether it should be real-time like WhatsApp or more asynchronous like email. How would you approach this?”
Evolving constraints: Like “You’ve designed a content recommendation system. Now imagine the dataset doubles every three months and latency requirements get stricter. How would your design adapt?”
Trade-off decisions: Like “Suppose you’re designing an API rate-limiting system. Your product team wants flexibility for power users, but infra wants strict enforcement. How would you balance these needs?”
Past experience reflection: Like “Tell me about a time you had to redesign or refactor a system because your initial assumptions didn’t hold. How did you identify the issue and fix it?”
You may not control these questions, but you can control your answer. Here’s a framework to follow when responding to scenario-based questions:

Clarify ambiguity: Start by making sure you fully understand the question. Ask clarifying questions about scale, latency, users, reliability, and other constraints if they aren’t provided.
State assumptions: When details are missing, explicitly state your assumptions. This shows the interviewer the rationale behind your decisions.
Structure your approach: Resist the urge to jump straight into specifics. Begin high-level by outlining components, data flow, and potential bottlenecks. Once the foundation is clear, dive into details like caching, databases, or messaging systems.
Discuss trade-offs: Show that you’re weighing options rather than reciting memorized solutions. Discussing trade-offs helps the interviewer follow your thought process and demonstrates critical thinking.
Connect to past experience: If you’ve built something similar, draw from that experience. Share lessons learned, key decisions made, and practical outcomes to ground your answer in reality.
Communicate clearly: Use diagrams or mental models to help paint a picture. A statement like “Imagine three layers: client, API gateway, and backend services” helps communicate your points clearly to your interviewer. Also, remember to summarize all the points you’ve discussed before finishing.
By following this framework, you demonstrate not only your technical knowledge but also your problem-solving approach, communication skills, and ability to make decisions under uncertainty.
Next steps
Remember: system design interviews are conversations, not tests with a single correct answer. Interviewers want to see how you think through complex problems, weigh trade-offs, and communicate your reasoning clearly. Practice explaining your thought process out loud, asking clarifying questions, and discussing the pros and cons of different approaches.
Even spending just 30 minutes a day on system concepts can make a big difference as your interview approaches. Feel free to mix things up to keep your preparation engaging:
Use system design flashcards to quiz yourself and reinforce key concepts.
Explore the system design roadmap to learn more about specific topics and understand patterns that appear across multiple systems.
With consistent practice and reflection, you’ll build the confidence and skills to approach any system design interview problems with clarity and composure.